
Introduction
There’s no argument against the importance of a well-textured world. Whether it’s procedural or hand-made, textures, normal maps, and variety are a must for a world to be entertaining. So, what are the problems I’ve found while texturing my world?
The problem
My first real attempt at texturing the world was, as expected, bad. Thankfully, because of the way the world is generated, I can extract the different biome masks that I would later use to place each texture. Initially, each biome had one texture. So, I went straightforwardly, generated a Texture2DArray, set it on the material, and sampled it on the shader. That was good as a first try, but there were a bunch of issues.
First, tiling was pretty apparent. I don’t have a picture to attach here, but it was clear how each texture was repeating itself. Secondly, there was no variation whatsoever around the same biome. All looked flat, with no cool lighting effects, no nothing. And finally, it looked awful. The textures were being warped around on the steeper sides, and with the tiling and no variation, it didn’t feel right. It didn’t feel professional.
So after some research, I added more steps to the shader. First, I added tri-planar mapping to remove the warping on the terrain, then I added cheap stochastic sampling to remove all apparent tiling. Next, I added normal maps so that each texture had some extra lighting direction. I also added height-map blending to make the transitions use the height of each texture to create a sensible transition instead of a simple blending. Finally, I made use of the nature of tri-planar mapping and added side textures to make more sloped areas look different.
Cool! Now everything looks good and runs perfectly. Oh, wait…
What’s that sound? Oh, my computer is overheating…
Yeah, after adding so many textures and different algorithms, I was doing too many things in that shader. It was slow.
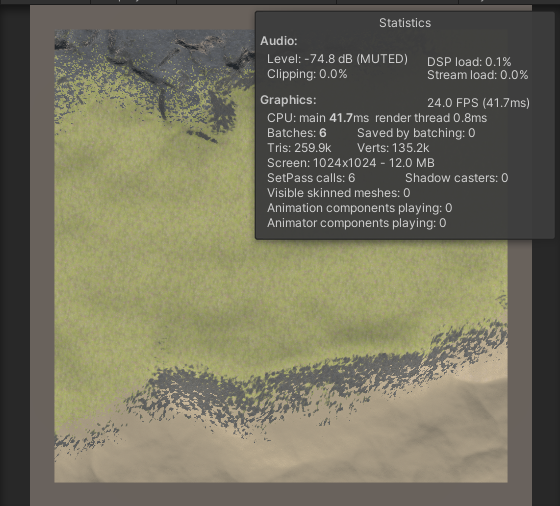
You can see here on the right that the game runs at approximately 20 fps, up and down, just to render the terrain and one chunk! I didn’t even try to load up the whole world, multiple chunks, and try to move. Compiling times of the shader were through the roof, so yeah, that was bad.
Time to optimize!

The first optimization
Stochastic sampling
Here you can see the original code used for stochastic sampling: (from u/rotoscope, Unity Stochastic Texture Sampling)
float4 tex2DStochastic(sampler2D tex, float2 UV)
{
//triangle vertices and blend weights
float4x3 BW_vx;
//uv transformed into triangular grid space with UV scaled by approximation of 2*sqrt(3)
float2 skewUV = mul(float2x2 (1.0 , 0.0 , -0.57735027 , 1.15470054), UV * 3.464);
//vertex IDs and barycentric coords
float2 vxID = float2 (floor(skewUV));
float3 barry = float3 (frac(skewUV), 0);
barry.z = 1.0-barry.x-barry.y;
BW_vx = ((barry.z>0) ?
float4x3(float3(vxID, 0),
float3(vxID + float2(0, 1), 0),
float3(vxID + float2(1, 0), 0), barry.zyx) :
float4x3(float3(vxID + float2 (1, 1), 0),
float3(vxID + float2 (1, 0), 0),
float3(vxID + float2 (0, 1), 0),
float3(-barry.z, 1.0-barry.y, 1.0-barry.x)));
//calculate derivatives to avoid triangular grid artifacts
float2 dx = ddx(UV);
float2 dy = ddy(UV);
//blend samples with calculated weights
return mul(tex2D(tex, UV + hash2D2D(BW_vx[0].xy), dx, dy), BW_vx[3].x) +
mul(tex2D(tex, UV + hash2D2D(BW_vx[1].xy), dx, dy), BW_vx[3].y) +
mul(tex2D(tex, UV + hash2D2D(BW_vx[2].xy), dx, dy), BW_vx[3].z);
}
This is pretty nice, but as you can see, the texture is only used at the end. We are running this too many times, and doing all of this math for each texture. However, all of the results of the function will be the same regardless of the texture. So first, let’s only do that math once.
We can create a struct containing the final useful values.
StochasticValue tex2DStochasticValues(float2 UV)
{
//triangle vertices and blend weights
float4x3 BW_vx;
//uv transformed into triangular grid space with UV scaled by approximation of 2*sqrt(3)
float2 skewUV = mul(float2x2 (1.0 , 0.0 , -0.57735027 , 1.15470054), UV * 3.464);
//vertex IDs and barycentric coords
float2 vxID = float2 (floor(skewUV));
float3 barry = float3 (frac(skewUV), 0);
barry.z = 1.0-barry.x-barry.y;
BW_vx = ((barry.z>0) ?
float4x3(float3(vxID, 0),
float3(vxID + float2(0, 1), 0),
float3(vxID + float2(1, 0), 0), barry.zyx) :
float4x3(float3(vxID + float2 (1, 1), 0),
float3(vxID + float2 (1, 0), 0),
float3(vxID + float2 (0, 1), 0),
float3(-barry.z, 1.0-barry.y, 1.0-barry.x)));
//calculate derivatives to avoid triangular grid artifacts
float2 dx = ddx(UV);
float2 dy = ddy(UV);
float2 uvTx1 = UV + hash2D2D(BW_vx[0].xy);
float2 uvTx2 = UV + hash2D2D(BW_vx[1].xy);
float2 uvTx3 = UV + hash2D2D(BW_vx[2].xy);
StochasticValue val; //Here i create the object with the final values
val.dd = float4(dx.x,dx.y, dy.x,dy.y);
val.BW = BW_vx[3];
val.uvTx1 = uvTx1;
val.uvTx2 = uvTx2;
val.uvTx3 = uvTx3;
return val;
}
struct StochasticValue{
float4 dd;
float3 BW;
float2 uvTx1;
float2 uvTx2;
float2 uvTx3;
};
And we can later use the object to generate the stochastic texture
float4 tex2DStochastic(StochasticValue val, Texture2DArray tex, SamplerState sampler_tex, int textureIndex)
{
return mul(tex.SampleGrad(sampler_tex, float3(val.uvTx1, textureIndex), val.dd.xy, val.dd.zw), val.BW.x) +
mul(tex.SampleGrad(sampler_tex, float3(val.uvTx2, textureIndex), val.dd.xy, val.dd.zw), val.BW.y) +
mul(tex.SampleGrad(sampler_tex, float3(val.uvTx3, textureIndex), val.dd.xy, val.dd.zw), val.BW.z);
}
What does that give us? Well, not that much… Some extra frames are always nice, but in the end, we just improved a part of it. There’s a lot more we can do, so let’s get going.
Skipping some parts
Well, the title of this chapter is pretty self-explanatory. A second optimization that gave some nice results was just skipping unnecessary steps. Adding conditionals in a shader is not recommended, but we can try it to see if it improves performance. From each mask, we can extract whether there is any weight or not by checking with a threshold. If the value on the mask is greater than the threshold, we can set a value on an array as 1; otherwise, as 0, and skip the next steps at that index.

💡 Why are conditionals a nono?
The way the GPU works with shaders is by parallelizing the same task to be done simultaneously in multiple cores. Therefore, if steps on the same line are vastly different from each other, it can slow down certain cores and, in general, everything. Basically, the more uniform the steps are, the better it can run in general. Conditionals break that similarity between steps, meaning that it might take longer in certain parts and, therefore, slow it down.
That actually is an improvement, and at one point I thought that was it. There’s nothing more that can be done. So I left it at that. But here comes solution number 2.
Baking it!
What first stood out to me was that all of these calculations were going to be made at each frame, meaning that a bunch of stuff that would never change was being calculated every single time the computer wanted to render an image. So my second attempt consisted of baking the whole texturing process.
Instead of doing it every time, I would do it once, take a picture of how it ends, store the new Texture2D, and then use that. I could bake normals too for extra features, and that would be fast and nice.
The process was quite simple. Following this article by Sneha Belkhale: Bake a pretty — or computationally challenging — shader into a texture (Unity), I modified my shader to bake the texture.
That was nice and fast, but it came with a lot of problems. First, generating a texture that looks right means using high-resolution height and width. Also, we lose mip map levels, (so that the texture looks fine automatically from far away), and close-up textures don’t look as good unless you use super high resolutions (8k or more), and that is a lot of memory for just basic texturing.
So, I was back to stage one. It was slow, computationally expensive, and really nothing good was coming out of it.
What is the point of something looking nice if it’s extremely slow?
The final solution
After doing some extra research, I found solutions to my problems.
Let’s roll back a bit and examine each problem that needs to be solved. The most computationally expensive thing in the shader is texture lookups, also known as “What color should the pixel at this position be?”.
How many texture look-ups was I doing initially? I had a world with 6 biomes, each biome had two textures: the flat and the side. Each texture had three sub-textures: the albedo (color), the normal map, and the height map.
That means 3 texture look-ups per tri-planar * 3 texture look-ups per stochastic sampling * 6 texture look-ups per each biome * 3 texture look-ups for the albedo, normal, and height + 6 look-ups for the biome masks, so approximately 168 texture look-ups every frame. I may have been skipping some, but that didn’t avoid the 54 texture look-ups for only the height values. Also, if I increase biomes, and therefore more textures, that’s even more look-ups, which is bad.
What are some ways to improve performance? Reduce that number!
The easiest one, biome masks
You see, I was storing each biome mask on its texture, so that meant more memory as we increased the number of textures and more lookups. First solution? Compact that. Instead of using a texture and storing the values on a singular channel, I could store each of the biome masks in a different channel, decreasing the number of lookups from 6 to 2.
public void Execute (int i) {
if(i > visualizationValuesR.Length-1)
return;
float4 currentR = visualizationValuesR[i];
float4 currentG = validG ? visualizationValuesG[i] : 0;
float4 currentB = validB ? visualizationValuesB[i] : 0;
float4 currentA = validA ? visualizationValuesA[i] : 0;
float4 r = ((currentR-minMaxValue.x)/(minMaxValue.y-minMaxValue.x))/maxWeight[i];
float4 g = ((currentG-minMaxValue.x)/(minMaxValue.y-minMaxValue.x))/maxWeight[i];
float4 b = ((currentB-minMaxValue.x)/(minMaxValue.y-minMaxValue.x))/maxWeight[i];
float4 a = ((currentA-minMaxValue.x)/(minMaxValue.y-minMaxValue.x))/maxWeight[i];
if(minMaxValue.y-minMaxValue.x != 0)
normalColor[i] = new Color4(r,g,b,a);
}

And although this is an improvement, the problem comes from all the multipliers, not the addition. But hey, an improvement is an improvement.
The concerning one, tri-planar mapping
The general approach for tri-planar mapping consists of something like this:
float4 triplanarTexture(sampler2D tex, sampler2D texY,TriplanarUV uv, float3 blendAxes)
{
float4 dx = tex2DStochastic(tex,uv.x)*blendAxes.x;
float4 dy = tex2DStochastic(texY,uv.y)*blendAxes.y;
float4 dz = tex2DStochastic(tex,uv.z)*blendAxes.z;
return dx+dy+dz;
}
You get three UV values and sample them three times for each direction, then add them together. This results in smooth control over when each thing is shown. However, in most cases, you are only sampling mainly from one direction, and if you are in the corners, you have a blend. So, if we can find the right UV and just sample from that, we would lose the blending, but we would reduce from 3 texture lookups to 1. Or in this case, since I’m doing stochastic sampling, from 9 to 3.
How do we do that? Well, like this Single Sample Seamless Tri-Planar Mapping (UE5)
//We get the triplanar UV
TriplanarUV triUv = GetTriplanarUV(IN.localCoord, IN.localNormal, _TextureScale);
//then find the blendAxes, or the weight of each plane, X, Y, Z
fixed3 blendAxes = GetWeights(IN.localNormal, _BlendOffset, _Power);
//then, we round to int, this results in a 1 or a 0 depending if the weight is big enough
int roundedX = round(blendAxes.x*(1-blendAxes.x) + blendAxes.x);
int roundedY = round(blendAxes.y*(1-blendAxes.y) + blendAxes.y);
float2 uv = lerp(lerp(triUv.z, triUv.x, roundedX), triUv.y, roundedY);
//And we just lerp accordingly, selecting the final highest uv according to the weight
StochasticValue val = tex2DStochasticValues(uv);
That’s pretty neat! Now we have tri-planar mapping with a single UV.
The drawback is that we get ugly seams between edges, but we will find a solution to that later on. For now, this works.

The obvious but I’m not sure why I didn’t see it, removing texture lookups
Yeah, I don’t know how I didn’t think about it, but the main problem is that I’m performing a texture lookup for everything every time, and I don’t need to do that. On the bright side, each texture lookup is done via an index. If I can modify the index to only consider the one that interests me the most, then I can save time.
Additionally, I realized that I don’t need to perform a texture lookup for height blending at the beginning of everything. If I can find a smarter way, I can eliminate that step.
What is most important initially are two things: the biome and the slope. Therefore, I can use these two values to determine the highest weights of their respective indexes.
for(int i = 0; i < biomeCount; i++)
{
half4 biomes = saturate(UNITY_SAMPLE_TEX2DARRAY(biomeMasks, fixed3(IN.textcoord, i)));
int textureIndexR = (i*4)*2;
int textureIndexG = (i*4+1)*2;
int textureIndexB = (i*4+2)*2;
int textureIndexA = (i*4+3)*2;
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexR, biomes.r*(blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexG, biomes.g*(blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexB, biomes.b*(blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexA, biomes.a*(blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexR+1, biomes.r*(1-blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexG+1, biomes.g*(1-blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexB+1, biomes.b*(1-blendAxes.y));
insertSorted(highestIndices, highestWeights, highestIndices,
highestWeights, textureIndexA+1, biomes.a*(1-blendAxes.y));
}
void insertSorted(out int4 indices, out half4 weight, in int4 originalIndices,
in half4 originalWeights, int newIndice, half newWeight)
{
indices = 0;
weight = 0;
int fourthPlace = saturate(ceil(newWeight-originalWeights.w));
int thirdPlace = saturate(ceil(newWeight-originalWeights.z));
int secondPlace = saturate(ceil(newWeight-originalWeights.y));
int firstPlace = saturate(ceil(newWeight-originalWeights.x));
weight.w = lerp(lerp(originalWeights.w, newWeight, fourthPlace), originalWeights.z,
saturate(thirdPlace+secondPlace+firstPlace));
weight.z = lerp(lerp(originalWeights.z, newWeight, thirdPlace), originalWeights.y,
saturate(secondPlace+firstPlace));
weight.y = lerp(lerp(originalWeights.y, newWeight, secondPlace), originalWeights.x, firstPlace);
weight.x = lerp(originalWeights.x, newWeight, firstPlace);
indices.w = lerp(lerp(originalIndices.w, newIndice, fourthPlace), originalIndices.z,
saturate(thirdPlace+secondPlace+firstPlace));
indices.z = lerp(lerp(originalIndices.z, newIndice, thirdPlace), originalIndices.y,
saturate(secondPlace+firstPlace));
indices.y = lerp(lerp(originalIndices.y, newIndice, secondPlace), originalIndices.x, firstPlace);
indices.x = lerp(originalIndices.x, newIndice, firstPlace);
}
Here, I’m calculating the different indices (since I now have only two textures for the biome), and I perform a sorted storage of the weights and indices.
💡 Why are you doing 8 instead of 4?
I store the textures in packs of two, with the first one representing the flat texture and the second one representing the slope texture. This way, I can easily access each texture by retrieving the index and adding one. After sorting all of them, they are automatically stored in the correct order with the appropriate index, and I can disregard the slope thereafter. You may notice that I’m using the blendAxes.y. That’s because it represents the smoothed version of the slope weight and ensures a smoother transition specifically along the Y axis.
With those indices calculated, I now only have to worry about 4 textures, which is good.
Next, I normalize the weights so that their sum adds up to one.
highestWeights /= highestWeights.x+highestWeights.y+highestWeights.z+highestWeights.w;
And now comes the cool part. Up until now, there has been a rough transition between textures. However, since the weights are smooth, combining all the textures will result in smooth transitions between each of them.
This opens up the opportunity to apply the technique of height blending!
float hR = triplanarTexture(textureHeights, sampler_textureHeights, val, highestIndices.r)*highestWeights.r;
float hG = triplanarTexture(textureHeights, sampler_textureHeights, val, highestIndices.g)*highestWeights.g;
float hB = triplanarTexture(textureHeights, sampler_textureHeights, val, highestIndices.b)*highestWeights.b;
float hA = triplanarTexture(textureHeights, sampler_textureHeights, val, highestIndices.a)*highestWeights.a;
height_start = max(height_start, max(max(max(hR, hG), hB), hA));
height_start -= _HeightBlendRange;
hR = max(hR-height_start, 0);
hG = max(hG-height_start, 0);
hB = max(hB-height_start, 0);
hA = max(hA-height_start, 0);
height_sum = hR+hG+hB+hA;
Here I get the height of each of the height map textures, then I find the maximum of all of them, find the point of transition, and get the final weights. You can read more of it in this post by Octopid: Height Blending Shader.
And now the final magic, I just use the correct indices, and weights, and generate the final texture.
half4 textureR = triplanarTexture(baseTextures, sampler_baseTextures, val, highestIndices.r)*(hR/height_sum);
half4 textureG = triplanarTexture(baseTextures, sampler_baseTextures, val, highestIndices.g)*(hG/height_sum);
half4 textureB = triplanarTexture(baseTextures, sampler_baseTextures, val, highestIndices.b)*(hB/height_sum);
half4 textureA = triplanarTexture(baseTextures, sampler_baseTextures, val, highestIndices.a)*(hA/height_sum);
half3 normalR = UnpackScaleNormal(triplanarTexture(textureNormals, sampler_textureNormals, val, highestIndices.r),
_NormalStrength)*(hR/height_sum);
half3 normalG = UnpackScaleNormal(triplanarTexture(textureNormals, sampler_textureNormals, val, highestIndices.g),
_NormalStrength)*(hG/height_sum);
half3 normalB = UnpackScaleNormal(triplanarTexture(textureNormals, sampler_textureNormals, val, highestIndices.b),
_NormalStrength)*(hB/height_sum);
half3 normalA = UnpackScaleNormal(triplanarTexture(textureNormals, sampler_textureNormals, val, highestIndices.a),
_NormalStrength)*(hA/height_sum);
c = textureR+textureG+textureB+textureA;
o.Normal = normalR+normalG+normalB+normalA;
Result?
Results
Initial Try

Final configuration
17.9 TIMES FASTER! That’s great :)
There are slight visual differences, but nothing too concerning. Also, some settings might be slightly different. However, the second method scales well. There will always be 36 texture lookups, no more, no less. As a result, it scales nicely with more biomes and textures. Moreover, I have access to bitmaps, making it easy to incorporate additional techniques from here.
I’m really happy with the results of all the optimizations. There’s still room for improvement, but since it runs smoothly, and works flawlessly in a real-time world, I’m going to leave it as it is.

Conclusion
This has been a huge learning process. I’ve been concerned about this for a long time, and it’s incredibly satisfying to finally have it working. My next step would be to revisit working on the vegetation since I think it might be broken.
But for now, that’s all! Thank you for reading.


